더미데이터란?
- 테스트나 시뮬레이션 목적으로 생성된 가짜 데이터를 의미합니다.
- 주로 시스템 동작 검증, 성능 테스트, 개발 초기 단계에서의 기능 확인 등을 위해 사용됩니다. 실제 데이터를 사용하지 않아도 되므로 개인정보 보호가 가능하며, 대량의 데이터를 손쉽게 생성하여 분석 및 테스트 환경을 구축할 수 있습니다.
테이블 및 데이터 이해
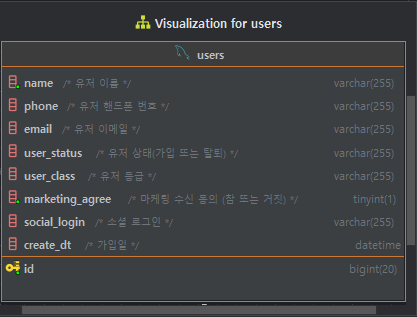
- name: 유저 이름
- phone: 유저 핸드폰 번호 (010-****-**** 형식)
- email: 유저 이메일
- user_status: 유저 상태 ('active', 'inactive', 'dormancy')
- user_class: 유저 등급 ('일반', 'Family', 'VIP', 'VVIP')
- marketing_agree: 마케팅 수신 동의 (0 or 1)
- social_login: 소셜 로그인 ('google', 'facebook', 'kakao', 'naver')
- create_at: 가입일
파이썬 라이브러리 설치
-
pip install Faker pandas sqlalchemy pymysql - 위와 같이 명령어를 입력하면 한 번에 모든 라이브러리가 설치됩니다.
1. Faker 라이브러리
-
pip install Faker - Faker는 가짜 데이터를 생성하는 라이브러리입니다.
- 주로 테스트나 데이터베이스에 샘플 데이터를 넣을 때 사용합니다.
- 예를 들어, 이름, 이메일, 주소, 전화번호 등 다양한 종류의 가짜 데이터를 만들 수 있습니다.
- 주요 기능
- 다양한 지역 언어와 문화에 맞는 데이터를 생성할 수 있습니다.
- ko_KR을 사용하면 한국어로 된 가짜 데이터를 생성할 수 있습니다.
2. pandas 라이브러리
-
pip install pandas - pandas는 데이터 분석 및 조작을 위한 Python 라이브러리입니다.
- 특히 구조화된 데이터를 다루는데 매우 유용하며, 주로 DataFrame이라는 자료구조를 사용해 데이터를 관리합니다.
- CSV, Excel 파일 등 다양한 형식의 데이터를 쉽게 읽고 쓸 수 있습니다.
- 주요 기능
- 데이터를 테이블 형식으로 저장하고 조작할 수 있습니다. (행과 열 기반)
- 데이터 필터링, 그룹화, 정렬, 결측값 처리 등 다양한 기능을 제공합니다.
- Excel, CSV, SQL 등 다양한 파일 형식으로 입출력이 가능합니다.
3. sqlalchemy 라이브러리
-
pip install sqlalchemy - SQLAlchemy는 Python에서 SQL을 사용하여 데이터베이스와 상호작용 하는데 사용되는 라이브러리입니다.
- SQLAlchemy는 두 가지 주요 기능을 제공합니다.
- ORM(Object-Relational Mapping): 객체지향 프로그래밍 방식으로 데이터베이스와 상호작용할 수 있게 해줍니다.
- SQL Expression Language: SQL 쿼리를 코드로 작성할 수 있게 해줍니다.
- 주요 기능
- Python 객체와 데이터베이스 테이블 간의 변화 (ORM 기능)
- SQL 쿼리의 표현식 언어를 제공
- 데이터베이스 연결 및 트랜잭션 관리
4. pymysql 라이브러리
-
pip install pymysql - PyMySQL은 Python에서 MySQL(Maria DB도 가능) 데이터베이스에 연결하고 쿼리를 실행할 수 있게 해주는 라이브러리입니다.
- SQLAlchemy에서 MySQL 데이터베이스와의 연결을 위해 사용할 수 있습니다.
- 주요 기능
- Python에서 MySQL 데이터베이스에 연결하고 쿼리를 실행
- MySQL 데이터베이스의 결과를 Python 객체로 변환
- 데이터베이스의 데이터를 읽고 쓰는 기능 제공
Faker를 이용한 더미 데이터 입력
1. 한국인 이름 생성 연습
- Faker의 name 함수 사용
더보기
from faker import Faker class DummyTest: def dummy_test(self): fake = Faker('ko_KR') # locale 정보 설정 Faker.seed() # 초기 seed 설정 name_list = [] repeat_count = 10 for i in range(repeat_count): name_list.append(fake.name()) # Faker를 이용하여 랜덤 이름 생성 후 리스트에 담기 print("랜덤 이메일: ", email_list) if __name__ == '__main__': dummy_test = DummyTest() dummy_test.dummy_test() ''' 출력 랜덤 이름: ['윤미영', '이종수', '김선영', '김은정', '김민지', '권민수', '이정수', '최옥순', '남상훈', '김영숙'] '''
2. 무료 이메일 주소 생성 연습
- Faker의 unique.free_email 함수 사용
더보기
from faker import Faker class DummyTest: def dummy_test(self): fake = Faker('ko_KR') # locale 정보 설정 Faker.seed() # 초기 seed 설정 email_list = [] repeat_count = 10 for i in range(repeat_count): email_list.append(fake.unique.free_email()) # Faker를 이용하여 랜덤 고유 이메일 생성 후 리스트에 담기 print("랜덤 입메일: ", email_list) if __name__ == '__main__': dummy_test = DummyTest() dummy_test.dummy_test() ''' 출력 랜덤 이메일: ['sanghogim@naver.com', 'sanghyeongim@hanmail.net', 'lgim@live.com', 'gimseongho@hotmail.com', 'imigyeong@gmail.com', 'vgwag@live.com', 'fgim@dreamwiz.com', 'vi@hotmail.com', 'jimingo@gmail.com', 'yejunhwang@dreamwiz.com'] '''
3. 입력에 필요한 더미 데이터 생성
- 핸드폰 번호: 010 이후 4자리-4자리 랜덤 숫자 조합을 생성하고, zfill을 통해 4자리 문자열 앞에 자리를 0으로 채워줍니다. (ex. 12 -> 0012, 123 -> 0123)
- 회원 등급: 4가지 등급으로 일반, Family, VIP, VVIP로 구분됩니다.
- 이메일: 고유한 이메일 주소 (xxx@xxx.com 형식)
- 마케팅 수신 동의: 0 또는 1 중 랜덤으로 값이 입력됩니다.
- 소셜 로그인: 4가지의 로그인 방법으로 google, facebook, kakao, naver 중에서 랜덤으로 값이 입력됩니다.
- 가입일: 현재 일자 기준 지난 1년 사이의 일자를 랜덤으로 입력됩니다.
더보기
from faker import Faker import random import pandas as pd class DummyDataToDB: def dummy_data_to_db(self): fake = Faker('ko_KR') Faker.seed(1) repeat_count = 100000 names = [fake.name() for _ in range(repeat_count)] phones = [ ('010' + '-' + str(random.randint(1, 9999)).zfill(4) + '-' + str(random.randint(1, 9999)).zfill(4)) for _ in range(repeat_count) ] emails = [fake.unique.free_email() for _ in range(repeat_count)] user_status = [random.choice(['active', 'inactive', 'dormancy']) for _ in range(repeat_count)] user_class = [random.choice(['일반', 'Family', 'VIP', 'VVIP']) for _ in range(repeat_count)] marketing_agree = [random.choice(['0', '1']) for _ in range(repeat_count)] social_login = [random.choice(['google', 'facebook', 'kakao', 'naver']) for _ in range(repeat_count)] create_dt = [fake.date_between(start_date='-1y', end_date='today') for _ in range(repeat_count)] df = pd.DataFrame({ 'name': names, 'phone': phones, 'email': emails, 'user_status': user_status, 'user_class': user_class, 'marketing_agree': marketing_agree, 'social_login': social_login, 'create_dt': create_dt }) print(df) ''' 출력 name phone ... social_login create_dt 0 홍정훈 010-4440-6436 ... google 2024-06-11 1 박영길 010-3666-5929 ... facebook 2024-08-02 2 안미숙 010-3943-1683 ... facebook 2024-09-17 3 전시우 010-6489-2343 ... facebook 2024-12-17 4 김영희 010-1355-0700 ... facebook 2024-11-01 ... ... ... ... ... ... 99995 이수민 010-6871-3529 ... google 2024-12-07 99996 김정식 010-0483-3926 ... naver 2024-10-11 99997 윤순자 010-2289-2260 ... naver 2024-10-13 99998 박광수 010-1576-9559 ... facebook 2024-08-11 99999 김도윤 010-6776-8588 ... google 2024-08-12 [100000 rows x 8 columns] '''
sqlalchemy를 이용한 데이터베이스에 입력
1. 데이터프레임 딕셔너리 변환
- 위에서 만든 데이터프레임 df 데이터를 to_dict 함수 파라미터로 넣어 딕셔너리 형태로 변환해줍니다.
더보기
from faker import Faker import random import pandas as pd class DummyDataToDB: def dummy_data_to_db(self): fake = Faker('ko_KR') Faker.seed(1) repeat_count = 100000 names = [fake.name() for _ in range(repeat_count)] phones = [ ('010' + '-' + str(random.randint(1, 9999)).zfill(4) + '-' + str(random.randint(1, 9999)).zfill(4)) for _ in range(repeat_count) ] emails = [fake.unique.free_email() for _ in range(repeat_count)] user_status = [random.choice(['active', 'inactive', 'dormancy']) for _ in range(repeat_count)] user_class = [random.choice(['일반', 'Family', 'VIP', 'VVIP']) for _ in range(repeat_count)] marketing_agree = [random.choice(['0', '1']) for _ in range(repeat_count)] social_login = [random.choice(['google', 'facebook', 'kakao', 'naver']) for _ in range(repeat_count)] create_dt = [fake.date_between(start_date='-1y', end_date='today') for _ in range(repeat_count)] df = pd.DataFrame({ 'name': names, 'phone': phones, 'email': emails, 'user_status': user_status, 'user_class': user_class, 'marketing_agree': marketing_agree, 'social_login': social_login, 'create_dt': create_dt }) records = df.to_dict(orient='records') print(records)
2. 데이터베이스 접속 정보 입력 (MariaDB)
- 데이터베이스랑 연결될 수 있도록 정보를 입력합니다.
더보기
from sqlalchemy import create_engine from constants import DBConstants class DummyDatabase: def dummy_database(self): db_constants = DBConstants() username = db_constants.DB_USERNAME password = db_constants.DB_PASSWORD host = db_constants.DB_HOST port = db_constants.DB_PORT database = db_constants.DB_NAME engine = create_engine(f"mysql+pymysql://{username}:{password}@{host}:{port}/{database}?charset=utf8mb4") return engine
3. 연결 및 데이터 입력
- 마지막으로 저장된 딕셔너리 형태의 데이터를 DB에 저장하는 방법입니다.
더보기
from faker import Faker import random import pandas as pd from data_processing.dummy_database import DummyDatabase from sqlalchemy import MetaData, insert class DummyDataToDB: def dummy_data_to_db(self): fake = Faker('ko_KR') Faker.seed(1) repeat_count = 100000 names = [fake.name() for _ in range(repeat_count)] phones = [ ('010' + '-' + str(random.randint(1, 9999)).zfill(4) + '-' + str(random.randint(1, 9999)).zfill(4)) for _ in range(repeat_count) ] emails = [fake.unique.free_email() for _ in range(repeat_count)] user_status = [random.choice(['active', 'inactive', 'dormancy']) for _ in range(repeat_count)] user_class = [random.choice(['일반', 'Family', 'VIP', 'VVIP']) for _ in range(repeat_count)] marketing_agree = [random.choice(['0', '1']) for _ in range(repeat_count)] social_login = [random.choice(['google', 'facebook', 'kakao', 'naver']) for _ in range(repeat_count)] create_dt = [fake.date_between(start_date='-1y', end_date='today') for _ in range(repeat_count)] df = pd.DataFrame({ 'name': names, 'phone': phones, 'email': emails, 'user_status': user_status, 'user_class': user_class, 'marketing_agree': marketing_agree, 'social_login': social_login, 'create_dt': create_dt }) records = df.to_dict(orient='records') dummy_db = DummyDatabase() engine = dummy_db.dummy_database() with engine.begin() as connection: metadata = MetaData() metadata.reflect(bind=engine) table = metadata.tables.get('users') if table is None: raise ValueError("Table 'users' does not exist in the database.") query = insert(table) result_proxy = connection.execute(query, records) print(f"{result_proxy.rowcount} rows inserted.")
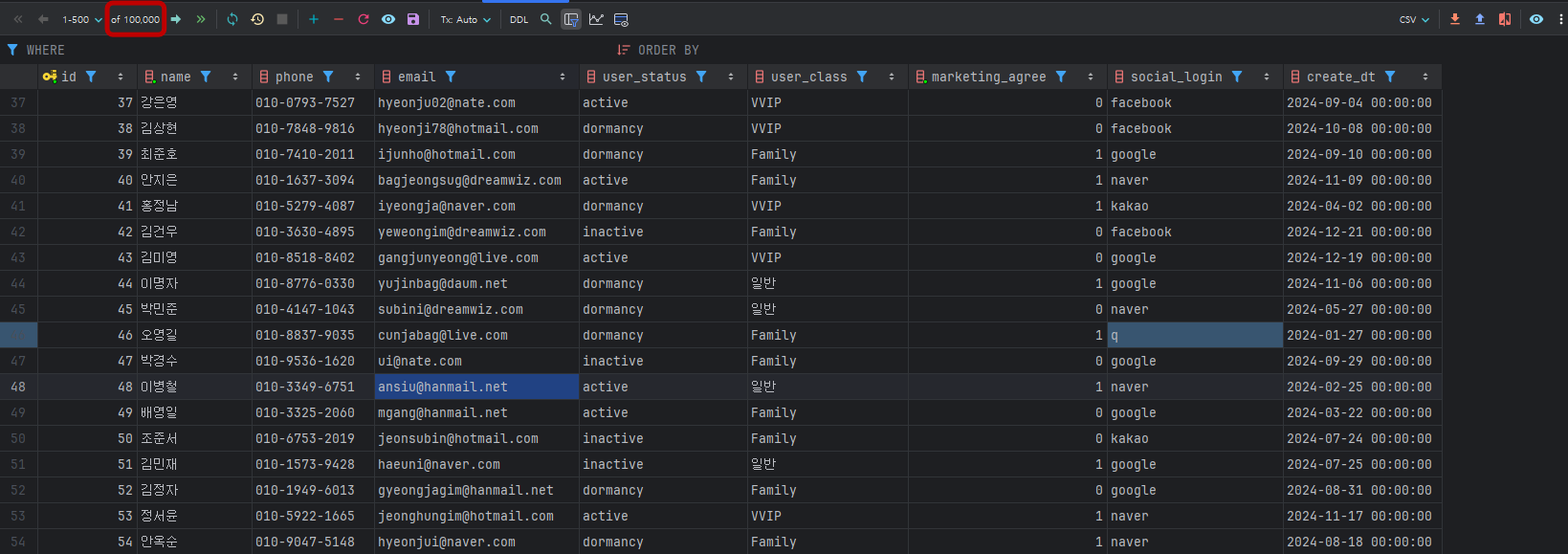
결과 확인
'Python' 카테고리의 다른 글
| [Python] - 파이썬 형태소 분석기 (2) | 2024.09.21 |
|---|---|
| [Python] - 파이참 인터프리터(Interpreter) 설정 (1) | 2024.09.20 |
| [Python] - 파이참 라이브러리 설치 (1) | 2024.09.09 |
| [Python] - 파이썬 기상청 Open API 활용 (0) | 2024.09.05 |
| [Python] - 파이썬 주석 (한줄, 여러줄, 단축키) (0) | 2024.09.02 |



